尚硅谷springboot3响应式编程
Reactor核心
前置知识
Lambda
Lambda表达式是Java8引入的一个重要特性;
Lambda表达式可以被视为匿名函数;
允许在需要函数的地方以更简洁的方式定义功能
java8语法糖:
1 | import java.util.*; |
函数式接口
在java中,函数式接口是只包含一个抽象方法的接口,他们是支持lambda表达式的基础,因为lamdba表达式需要一个目标类型,这个目标类型必须是一个函数式接口。
java.util.function包下的函数式接口一共分为三大类:
- Consumer:消费者
- Supplier:提供者
- Predicate:断言
get/test/apply/accept调用的函数方法;
jdk提供的函数式接口
| Consumer BiConsumer IntConsumer LongConsumer DoubleConsumer ObjDoubleConsumer ObjIntConsumer ObjLongConsumer |
Function BiFunction IntFunction LongFunction DoubleFunction IntToDoubleFunction IntToLongFunction DoubleToIntFunction DoubleToLongFunction LongToDoubleFunction LongToIntFunction ToDoubleBiFunction ToDoubleFunction ToIntBiFunction ToIntFunction ToLongBiFunction ToLongFunction |
Supplier LongSupplier BooleanSupplier DoubleSupplier IntSupplier |
Predicate BiPredicate IntPredicate LongPredicate DoublePredicate |
UnaryOperator IntUnaryOperator LongUnaryOperator DoubleUnaryOperator BinaryOperator IntBinaryOperator LongBinaryOperator DoubleBinaryOperator |
Consumer
- 有入参,无出参(消费者):Consumer.accept
1 | Consumer<String> consumer = (String s) -> { |
Function
- 有入参,有出参(多功能函数):Function.apply
1 | Function<String,Integer> function = (String x) -> Integer.parseInt(x); |
Runnable
- 无入参,无出参(普通函数):Runnable.run
1 | Runnable runnable = () -> System.out.println("aaa"); |
Supplier
- 无入参,有出参(提供者):Supplier.get
1 | Supplier<String> supplier = ()-> UUID.randomUUID().toString(); |
Predicate
- 断言,输入一个数据,返回布尔:Predicate.test
1
2
3
4Predicate<Integer> predicate = i -> i%2==0;
if (predicate.test(10)){
System.out.println("偶数");
}
BiXxxxx
基于上面的几个函数进行扩展,可以有两个入参
1 | BiConsumer<String,String> function = (a,b)->{ //能接受两个入参 |
NnnXxxx
入参由泛型固定为Nnn(某一种基本或者封装类型)类型,例如DoubleConsumer,将泛型固定为Double
1 | DoubleConsumer doubleConsumer = (double d) -> { |
StreamAPI
声明式处理集合数据,包括:筛选、转换、组合等。
- Stream Pipeline:流管道、流水线
- Intermediate Operations:中间操作
- Terminal Operation:终止操作
Stream所有数据和操作被组合成流管道
流管道组成:
- 一个数据源(可以是一个数组、集合、生成器函数、I/O管道)
- 零或多个中间操作(将一个流变形成另一个流)
- 一个终止操作(产生最终结果)
流是惰性的;只有在启动最终操作时才会对源数据进行计算,而且只在需要时才会消耗源元素
一个流只能被操作一次
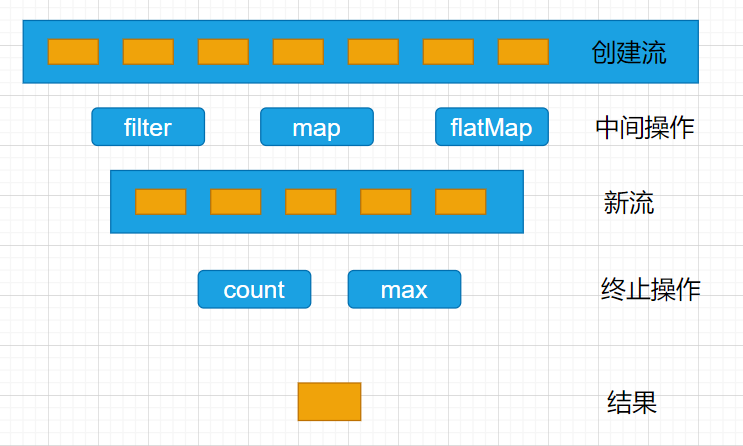
最佳实战:以后凡是写for循环处理数据的,统一全部用StreamAPI进行替换;
Stream所有数据和操作被组合成流管道组成:
- 一个数据源(可以是一个数组、集合、生成器函数、I/O管道)
- 零或多个中间操作(将一个流变成另一个流)
- 一个终止操作(产生最终结果)
中间操作:Intermediate Operations
- filter:过滤;跳出我们需要的元素
- map:映射;一一映射,a变成b
- mapToInt、mapToLong、mapToDouble
- flatMap:打散、散列、展开、扩维:一对多映射
1 | filter、 |
| 方法 | 描述 |
|---|---|
| filter | 过滤,挑出需要的元素,入参返回一个布尔类型, |
| map | 映射,一一映射,a变成b,有一个入参必须有一个出参 |
| mapToInt | 映射,将其他类型映射成int,转为IntStream,可以进行一些int相关的操作 |
| mapToLong | 与上面类似,不过是转成LongStream |
| mapToDouble | 与上面类型,转成DoubleStream |
| flatMap | 打散、散列、展开、扩维:一对多映射(将一个元素扩展为一个流,然后再将所有的流收集合并) |
| flatMapToInt | 作用与上一样,不过扩展出的流为IntStream |
| flatMapToLong | 作用与上一样,不过扩展出的流为LongStream |
| flatMapToDouble | 作用与上一样,不过扩展出的流为DoubleStream |
| mapMulti | 内部调用flatMap进行处理,两个参数,第一个是元素,第二个是一个buffer,往buffer里面放什么,最后就会返回什么(总体功能和flatMap类似) |
| mapMultiToInt | 限制buffer中的参数为int,并且内部调用的是flatMapToInt |
| mapMultiToLong | 限制buffer中的参数为Long,并且内部调用的是flatMapToLong |
| mapMultiToDouble | 限制buffer中的参数为Double,并且内部调用的是flatMapToDounble |
| parallel | 开启并发流 |
| unordered | 消除顺序限制,不再保证顺序(并不会打乱流的顺序,而是不再保证顺序) |
| onClose | 回调方法,当流的中间操作以及终结操作结束之后,会回调该方法 |
| sequential | 将并行流转为串行流,强制后续操作有序执行 |
| distinct | 去重 |
| sorted | 排序 |
| peek | 消费执行,不会改变流的类型 |
| limit | 分页,限制流中元素的数量,超出的将舍弃 |
| skip | 跳过,跳过流中前几个元素 |
| takeWhile | 满足条件时取出元素,当遇到第一个不满足条件的元素后,将忽略后面所有元素 |
| dropWhile | 忽略满足条件的元素,直到第一个不满足条件的元素出现,将不再忽略后面的元素 |
终止操作:Terminal Operation
1 | forEach、forEachOrdered、toArray、reduce、collect、toList、min、 |
| 方法 | 描述 |
|---|---|
| forEach | 循环遍历元素 |
| forEachOrdered | 有序遍历元素(按照元素在流中的顺序) |
| toArray | 将流中元素转为数组 |
| reduce | 将流中元素进行累计,生成一个单一的结果 |
| collect | 把流转换成某一种集合或者具体操作 |
| toList | 把流转换成list集合 |
| min | 取流中最小的元素 |
| max | 取流中最大的元素 |
| count | 取流中元素的个数 |
| anyMatch | 判断流中元素是否符合某个条件,只要有一个元素符合条件即返回true |
| allMatch | 同上,不过需要流中所有元素都符合条件才会返回true |
| noneMatch | 当流为空,或者流中所有元素都不符合条件时,返回true |
| findFirst | 返回流中第一个元素,串行流是会返回第一个,会返回第一个处理完成的元素,如果同时有多个完成,则返回原始数据中最靠前的 |
| findAny | 返回第一个元素,串行流时和findFirst类似,并行流时会选择第一个,不在意顺序 |
| iterator | 获取流元素的迭代器 |
流与集合:
- 集合关注高效数据管理和访问;
- 流没有提供直接访问或操作其元素的手段,关注声明性地描述源头数据的一系列操作。
创建流
| 方法 | 描述 |
|---|---|
| Stream.of() | 创建流并通过可变数组设置流内的元素 |
| Stream.builder() | 创建流,可以通过add方法设置元素,最后通过build方法创建流 |
| Stream.empty() | 创建一个空流 |
| Stream.ofNullable() | 创建一个可能为空的流,如果方法中的元素为空,则是空流,如果不为空则包含元素 |
| Stream.generate() | 通过函数式接口创建流,具体创建流的逻辑可以写在函数式接口中延迟调用 |
| Stream.concat() | 将两个流拼接成一个新流 |
| Collection.stream() | 通过集合对象创建流,集合内的数据即为流中的元素 |
流与集合
- 集合关注高效数据管理和访问
- 流没有提供直接访问或操作其元素的手段,关注声明性的描述源头数据的一系列操作
Reactive-Stream
Reactive Stream是JVM面向流的库的标准和规范
- 处理可能无限数量的元素
- 有序
- 在组件之间异步传递元素
- 强制性非阻塞,背压模式
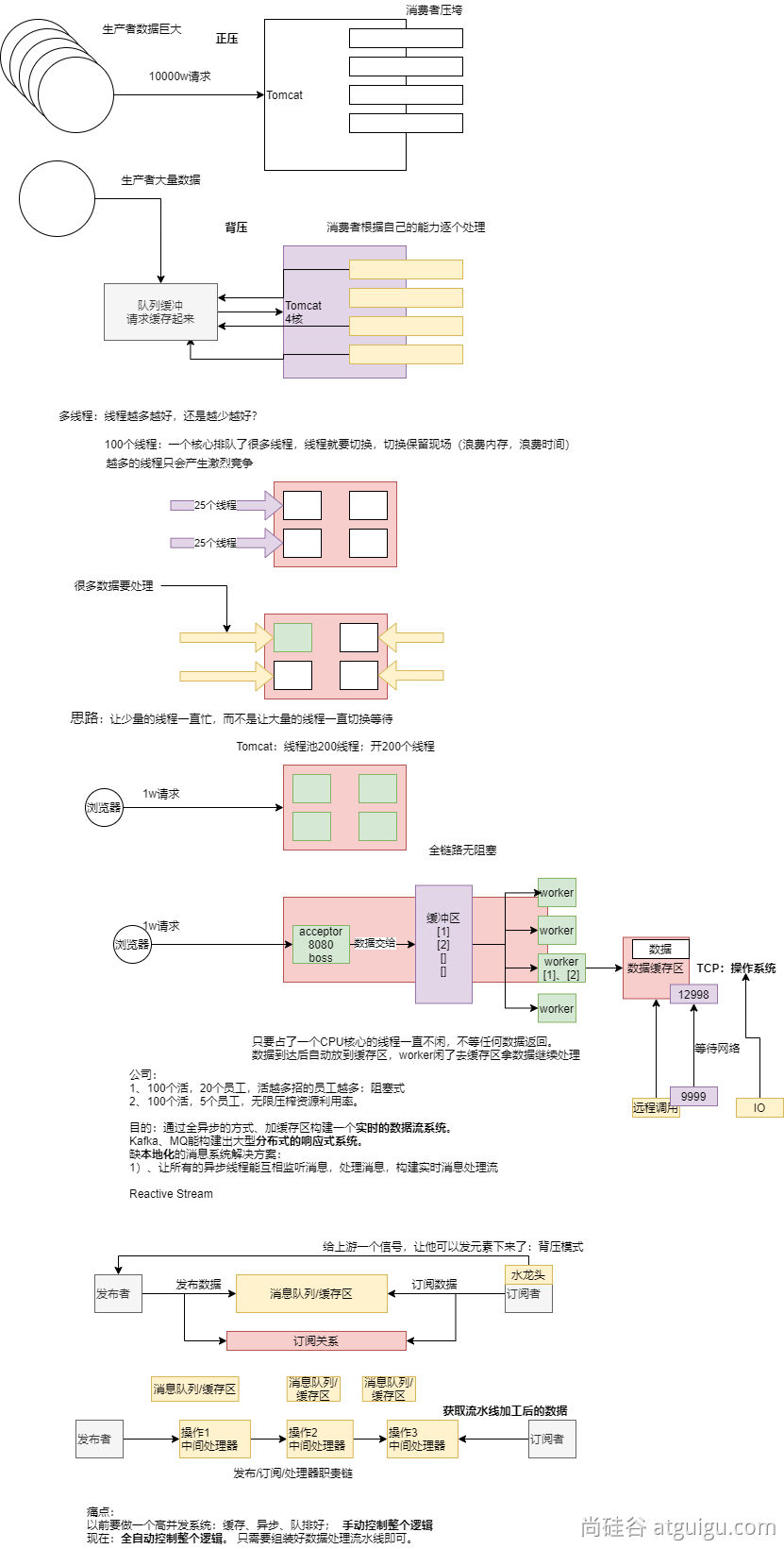
基于异步、消息驱动的全事件回调系统:响应式系统
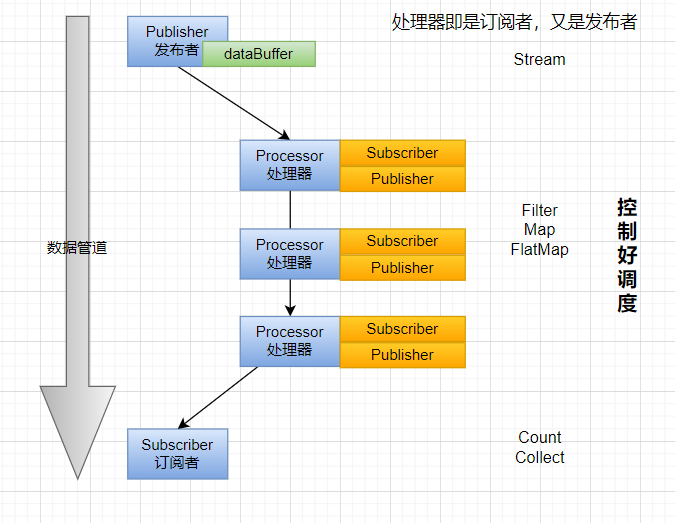
Reactive-Stream组件
- Publisher:发布者;产生数据流
- Subscriber:订阅者;消费数据流
- Subscription:订阅关系;
- 订阅关系是发布者和订阅者之间的关联接口;订阅者通过订阅来表示对发布者产生的数据感兴趣;订阅者可以请求一定数量的元素,也可以取消订阅。
- Processor:处理器;
- 处理器是同时实现了发布者和订阅者接口的组件;它可以接收来自一个发布者的数据,进行处理,并将结果发布给下一个订阅者;处理器在Reactor中充当中间环节,代表一个处理阶段,允许你在数据流中进行转换、过滤和其他操作。
这种模型遵循Reactive-Stream规范,确保了异步流的一致性和可靠性。
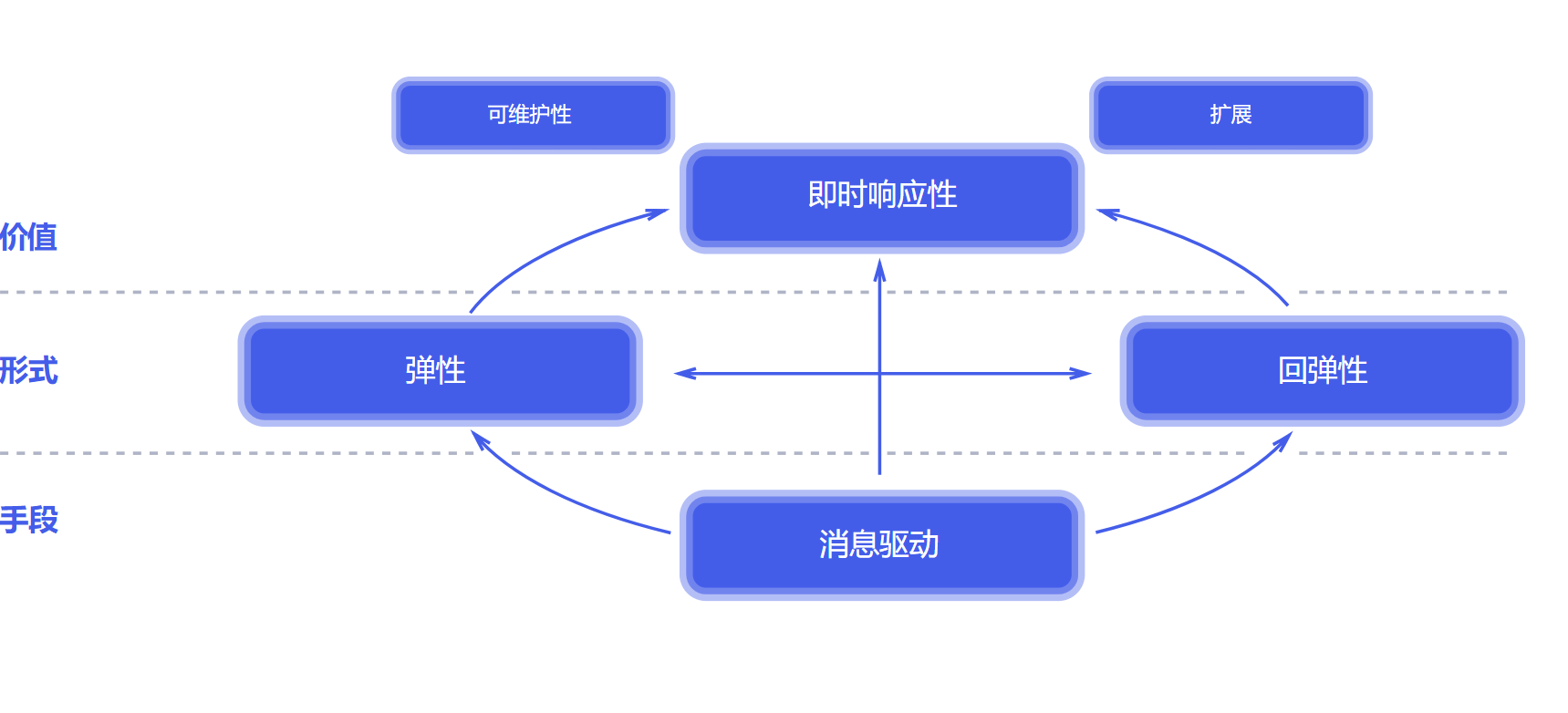
响应式编程
- 底层:基于数据缓冲队列 + 消息驱动模型 + 异步回调机制
- 编码:流式编程 + 链式调用 + 声明式API
- 效果:优雅全异步 + 消息实时处理 + 高吞吐量 + 占用少量资源
Reactor
Reactor是基于Reactive Stream的第四代响应式库规范,用于在JVM上构建非阻塞应用程序;Project Reactor
- 完全非阻塞的,并提供高效的需求管理,它直接与java的功能API、CompletableFuture、Stream和Duration交互。
- Reactor提供了两种响应式和可组合的API,Flux[N]和Mono[0|1]
- 适合微服务,提供基于netty背压机制网络引擎(HTTP、TCP、UDP)
主要概念:
- 发布者(Publisher)
- 订阅者(Subscriber)
- 订阅关系(Subscription)
- 处理器(Processor)
- 调度器(Scheduler)
- 事件/信号(event/signal)
- 序列/流(sequence/stream)
- 元素(element/item)
- 操作符(operator)
快速上手
介绍
Reactor是一个用于JVM的完全非阻塞的响应式编程框架,具备高效的需求管理(即对“背压(backpressure)”的控制)能力。它与Java8函数式API直接集成,比如CompletableFuture、Stream 以及 Duration。它提供了异步序列API Flux(用于[N]个元素)和 Mono (用于[0|1]个元素),并完全遵循和实现了“响应式扩展规范”(Reactive Extensions Specification)。
Reactor 的 reactor-ipc 组件还支持非阻塞的进程间通信(inter-process communication, IPC)。 Reactor IPC 为 HTTP(包括 Websockets)、TCP 和 UDP 提供了支持背压的网络引擎,从而适合 应用于微服务架构。并且完整支持响应式编解码(reactive encoding and decoding)。
依赖
1 | <dependencyManagement> |
响应式编程
响应式编程是一种关注于 数据流(data streams) 和 变化传递(propagation of change) 的 异步编程 方式。
这意味着它可以用既有的编程语言表达静态(如数组)或动态(如事件源)的数据流。
了解历史:
- 在响应式编程方面,微软跨出了第一步,它在 .NET 生态中创建了响应式扩展库(Reactive Extensions library, Rx)。接着 RxJava 在JVM上实现了响应式编程。后来,在 JVM 平台出现了一套标准的响应式编程规范,它定义了一系列标准接口和交互规范。并整合到 Java 9 中(使用 Flow 类)。
- 响应式编程通常作为面向对象编程中的“观察者模式”(Observer design pattern)的一种扩展。 响应式流(reactive streams)与“迭代子模式”(Iterator design pattern)也有相通之处, 因为其中也有 Iterable-Iterator 这样的对应关系。主要的区别在于,Iterator 是基于 “拉取”(pull)方式的,而响应式流是基于“推送”(push)方式的。
- 使用 iterator 是一种“命令式”(imperative)编程范式,即使访问元素的方法是 Iterable 的唯一职责。关键在于,什么时候执行 next() 获取元素取决于开发者。在响应式流中,相对应的 角色是 Publisher-Subscriber,但是 当有新的值到来的时候 ,却反过来由发布者(Publisher) 通知订阅者(Subscriber),这种“推送”模式是响应式的关键。此外,对推送来的数据的操作 是通过一种声明式(declaratively)而不是命令式(imperatively)的方式表达的:开发者通过 描述“控制流程”来定义对数据流的处理逻辑。
- 除了数据推送,对错误处理(error handling)和完成(completion)信号的定义也很完善。 一个 Publisher 可以推送新的值到它的 Subscriber(调用 onNext 方法), 同样也可以推送错误(调用 onError 方法)和完成(调用 onComplete 方法)信号。 错误和完成信号都可以终止响应式流。
阻塞是对资源的浪费
现代应用需要应对大量的并发用户,而且即使现代硬件的处理能力飞速发展,软件性能仍然是关键因素。
广义来说我们有两种思路来提升程序性能:
- 并行化(parallelize) :使用更多的线程和硬件资源。[异步]
- 基于现有的资源来 提高执行效率 。
通常,Java开发者使用阻塞式(blocking)编写代码。这没有问题,在出现性能瓶颈后, 我们可以增加处理线程,线程中同样是阻塞的代码。但是这种使用资源的方式会迅速面临 资源竞争和并发问题。
更糟糕的是,阻塞会浪费资源。具体来说,比如当一个程序面临延迟(通常是I/O方面, 比如数据库读写请求或网络调用),所在线程需要进入 idle 状态等待数据,从而浪费资源。
所以,并行化方式并非银弹。这是挖掘硬件潜力的方式,但是却带来了复杂性,而且容易造成浪费。
异步可以解决问题吗?
第二种思路——提高执行效率——可以解决资源浪费问题。通过编写 异步非阻塞 的代码, (任务发起异步调用后)执行过程会切换到另一个 使用同样底层资源 的活跃任务,然后等 异步调用返回结果再去处理。
但是在 JVM 上如何编写异步代码呢?Java 提供了两种异步编程方式:
- 回调(Callbacks) :异步方法没有返回值,而是采用一个 callback 作为参数(lambda 或匿名类),当结果出来后回调这个 callback。常见的例子比如 Swings 的 EventListener。
- Futures :异步方法 立即 返回一个 Future<T> ,该异步方法要返回结果的是 T 类型,通过 Future封装。这个结果并不是 立刻 可以拿到,而是等实际处理结束才可用。比如, ExecutorService 执行 Callable<T> 任务时会返回 Future 对象。
这些技术够用吗?并非对于每个用例都是如此,两种方式都有局限性。
回调很难组合起来,因为很快就会导致代码难以理解和维护(即所谓的“回调地狱(callback hell)”)。
考虑这样一种情景:
- 在用户界面上显示用户的5个收藏,或者如果没有任何收藏提供5个建议。
- 这需要3个 服务(一个提供收藏的ID列表,第二个服务获取收藏内容,第三个提供建议内容):
回调地狱(Callback Hell)的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37userService.getFavorites(userId, new Callback<List<String>>() {
public void onSuccess(List<String> list) {
if (list.isEmpty()) {
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) {
UiUtils.submitOnUiThread(() -> {
list.stream()
.limit(5)
.forEach(uiList::show);
});
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
} else {
list.stream()
.limit(5)
.forEach(favId -> favoriteService.getDetails(favId,
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
Reactor改造后为:
1 | userService.getFavorites(userId) |
如果你想确保“收藏的ID”的数据在800ms内获得(如果超时,从缓存中获取)呢?在基于回调的代码中, 会比较复杂。但 Reactor 中就很简单,在处理链中增加一个 timeout 的操作符即可。
1 | userService.getFavorites(userId) |
额外扩展:
Futures 比回调要好一点,但即使在 Java 8 引入了 CompletableFuture,它对于多个处理的组合仍不够好用。 编排多个 Futures 是可行的,但却不易。此外,Future 还有一个问题:当对 Future 对象最终调用 get() 方法时,仍然会导致阻塞,并且缺乏对多个值以及更进一步对错误的处理。
考虑另外一个例子,我们首先得到 ID 的列表,然后通过它进一步获取到“对应的 name 和 statistics” 为元素的列表,整个过程用异步方式来实现。
CompletableFuture 处理组合的例子 :
1 | CompletableFuture<List<String>> ids = ifhIds(); |
从命令式编程到响应式编程
类似 Reactor 这样的响应式库的目标就是要弥补上述“经典”的 JVM 异步方式所带来的不足, 此外还会关注一下几个方面:
- 可编排性(Composability) 以及 可读性(Readability)
- 使用丰富的 操作符 来处理形如 流 的数据
- 在 订阅(subscribe) 之前什么都不会发生
- 背压(backpressure) 具体来说即 消费者能够反向告知生产者生产内容的速度的能力
- 高层次 (同时也是有高价值的)的抽象,从而达到 并发无关 的效果
可编排性与可读性
可编排性,指的是编排多个异步任务的能力。比如我们将前一个任务的结果传递给后一个任务作为输入, 或者将多个任务以分解再汇总(fork-join)的形式执行,或者将异步的任务作为离散的组件在系统中 进行重用。
这种编排任务的能力与代码的可读性和可维护性是紧密相关的。随着异步处理任务数量和复杂度 的提高,编写和阅读代码都变得越来越困难。就像我们刚才看到的,回调模式是简单的,但是缺点 是在复杂的处理逻辑中,回调中会层层嵌入回调,导致 回调地狱(Callback Hell) 。你能猜到 (或有过这种痛苦经历),这样的代码是难以阅读和分析的。
Reactor 提供了丰富的编排操作,从而代码直观反映了处理流程,并且所有的操作保持在同一层次 (尽量避免了嵌套)。
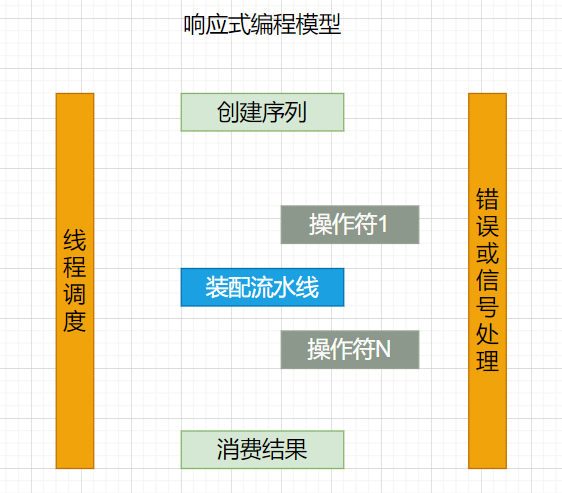
就像装配流水线
你可以想象数据在响应式应用中的处理,就像流过一条装配流水线。Reactor 既是传送带, 又是一个个的装配工或机器人。原材料从源头(最初的 Publisher)流出,最终被加工为成品, 等待被推送到消费者(或者说 Subscriber)。
原材料会经过不同的中间处理过程,或者作为半成品与其他半成品进行组装。如果某处有齿轮卡住, 或者某件产品的包装过程花费了太久时间,相应的工位就可以向上游发出信号来限制或停止发出原材料。
操作符(Operators)
在 Reactor 中,操作符(operator)就像装配线中的工位(操作员或装配机器人)。每一个操作符 对 Publisher 进行相应的处理,然后将 Publisher 包装为一个新的 Publisher。就像一个链条, 数据源自第一个 Publisher,然后顺链条而下,在每个环节进行相应的处理。最终,一个订阅者 (Subscriber)终结这个过程。请记住,在订阅者(Subscriber)订阅(subscribe)到一个 发布者(Publisher)之前,什么都不会发生。
理解了操作符会创建新的 Publisher 实例这一点,能够帮助你避免一个常见的问题, 这种问题会让你觉得处理链上的某个操作符没有起作用。
虽然响应式流规范(Reactive Streams specification)没有规定任何操作符, 类似 Reactor 这样的响应式库所带来的最大附加价值之一就是提供丰富的操作符。包括基础的转换操作, 到过滤操作,甚至复杂的编排和错误处理操作。
subscribe() 之前什么都不会发生
在 Reactor 中,当你创建了一条 Publisher 处理链,数据还不会开始生成。事实上,你是创建了 一种抽象的对于异步处理流程的描述(从而方便重用和组装)。
当真正“订阅(subscrib)”的时候,你需要将 Publisher 关联到一个 Subscriber 上,然后 才会触发整个链的流动。这时候,Subscriber 会向上游发送一个 request 信号,一直到达源头 的 Publisher。
背压
向上游传递信号这一点也被用于实现 背压 ,就像在装配线上,某个工位的处理速度如果慢于流水线 速度,会对上游发送反馈信号一样。
在响应式流规范中实际定义的机制同刚才的类比非常接近:订阅者可以无限接受数据并让它的源头 “满负荷”推送所有的数据,也可以通过使用 request 机制来告知源头它一次最多能够处理 n 个元素。
中间环节的操作也可以影响 request。想象一个能够将每10个元素分批打包的缓存(buffer)操作。 如果订阅者请求一个元素,那么对于源头来说可以生成10个元素。此外预取策略也可以使用了, 比如在订阅前预先生成元素。
这样能够将“推送”模式转换为“推送+拉取”混合的模式,如果下游准备好了,可以从上游拉取 n 个元素;但是如果上游元素还没有准备好,下游还是要等待上游的推送。
热(Hot) vs 冷(Cold)
在 Rx 家族的响应式库中,响应式流分为“热”和“冷”两种类型,区别主要在于响应式流如何 对订阅者进行响应:
- 一个“冷”的序列,指对于每一个 Subscriber,都会收到从头开始所有的数据。如果源头 生成了一个 HTTP 请求,对于每一个订阅都会创建一个新的 HTTP 请求。
- 一个“热”的序列,指对于一个 Subscriber,只能获取从它开始 订阅 之后 发出的数据。不过注意,有些“热”的响应式流可以缓存部分或全部历史数据。 通常意义上来说,一个“热”的响应式流,甚至在即使没有订阅者接收数据的情况下,也可以 发出数据(这一点同 “Subscribe() 之前什么都不会发生”的规则有冲突)。
核心特性
Mono和Flux
Mono: 0|1 数据流
Flux: N数据流
响应式流:元素(内容) + 信号(完成/异常);
subscribe()
自定义流的信号感知回调
1 | flux.subscribe( |
自定义消费者
1 | flux.subscribe(new BaseSubscriber<String>() { |
流的取消
消费者调用 cancle() 取消流的订阅;
Disposable
1 | Flux<String> flux = Flux.range(1, 10) |
BaseSubscriber
自定义消费者,推荐直接编写 BaseSubscriber 的逻辑;
背压(Backpressure )和请求重塑(Reshape Requests)
buffer:缓冲
1 | Flux<List<Integer>> flux = Flux.range(1, 10) //原始流10个 |
limit:限流
1 | Flux.range(1, 1000) |
以编程方式创建序列-Sink
Sink.next
Sink.complete
同步环境-generate
多线程-create
handle()
自定义流中元素处理规则
1 | // |
自定义线程调度
响应式:响应式编程: 全异步、消息、事件回调
默认还是用当前线程,生成整个流、发布流、流操作
1 | public void thread1(){ |
错误处理
命令式编程:常见的错误处理方式
Catch and return a static default value. 捕获异常返回一个静态默认值
1 | try { |
onErrorReturn: 实现上面效果,错误的时候返回一个值
1、吃掉异常,消费者无异常感知
2、返回一个兜底默认值
3、流正常完成;
1 | Flux.just(1, 2, 0, 4) |
Catch and execute an alternative path with a fallback method. 吃掉异常,执行一个兜底方法;
1 | try { |
onErrorResume
1、吃掉异常,消费者无异常感知
2、调用一个兜底方法
3、流正常完成
1 | Flux.just(1, 2, 0, 4) |
Catch and dynamically compute a fallback value. 捕获并动态计算一个返回值
根据错误返回一个新值
1 | try { |
1 | .onErrorResume(err -> Flux.error(new BusinessException(err.getMessage()+":炸了"))) |
1、吃掉异常,消费者有感知
2、调用一个自定义方法
3、流异常完成
Catch, wrap to a BusinessException, and re-throw. 捕获并包装成一个业务异常,并重新抛出
1 | try { |
包装重新抛出异常: 推荐用 .onErrorMap
1、吃掉异常,消费者有感知
2、抛新异常
3、流异常完成
1 | .onErrorResume(err -> Flux.error(new BusinessException(err.getMessage()+":炸了"))) |
Catch, log an error-specific message, and re-throw. 捕获异常,记录特殊的错误日志,重新抛出
1 | try { |
异常被捕获、做自己的事情
不影响异常继续顺着流水线传播
1、不吃掉异常,只在异常发生的时候做一件事,消费者有感知
Use the finally block to clean up resources or a Java 7 “try-with-resource” construct.
1 | Flux.just(1, 2, 3, 4) |
忽略当前异常,仅通知记录,继续推进
1 | Flux.just(1,2,3,0,5) |
常用操作
filter、flatMap、concatMap、flatMapMany、transform、defaultIfEmpty、switchIfEmpty、concat、concatWith、merge、mergeWith、mergeSequential、zip、zipWith…
Context-API:响应式中的ThreadLocal
- ThreadLocal机制失效(响应式编程是基于异步的,ThreadLocal只能在同线程内调用,所以响应式编程中无法使用)
1
2
3
4
5
6
7
8
9
10Flux.just(1,2,3)
.transformDeferredContextual((flux,context)->{
System.out.println("flux = " + flux);
System.out.println("context = " + context);
return flux.map(i->i+"==>"+context.get("prefix"));
})
//上游能拿到下游的最近一次数据
.contextWrite(Context.of("prefix","哈哈"))
//ThreadLocal共享了数据,上游的所有人能看到; Context由下游传播给上游
.subscribe(v-> System.out.println("v = " + v));
ParallelFlux
- 并行流
1
2
3
4
5
6Flux.range(1,1000000)
.buffer(100)
.parallel(8)
.runOn(Schedulers.newParallel("yy"))
.log()
.subscribe();
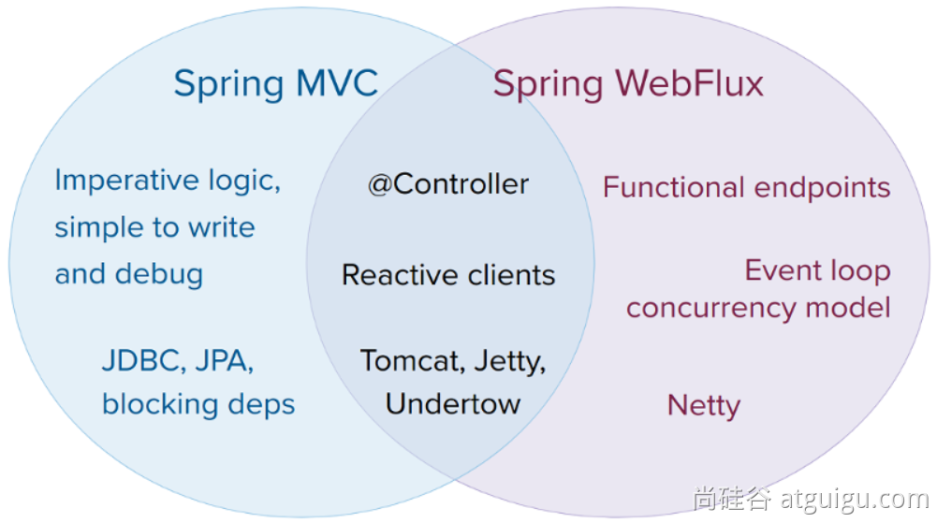
Spring Webflux
WebFlux:底层完全基于netty+reactor+springweb 完成一个全异步非阻塞的web响应式框架
底层:异步 + 消息队列(内存) + 事件回调机制 = 整套系统
优点:能使用少量资源处理大量请求;
组件对比
| API功能 | Servlet-阻塞式Web | WebFlux-响应式Web |
|---|---|---|
| 前端控制器 | DispatcherServlet | DispatcherHandler |
| 处理器 | Controller | WebHandler/Controller |
| 请求、响应 | ServletRequest、ServletResponse | ServerWebExchange: ServerHttpRequest、ServerHttpResponse |
| 过滤器 | Filter(HttpFilter) | WebFilter |
| 异常处理器 | HandlerExceptionResolver | DispatchExceptionHandler |
| Web配置 | @EnableWebMvc | @EnableWebFlux |
| 自定义配置 | WebMvcConfigurer | WebFluxConfigurer |
| 返回结果 | 任意 | Mono、Flux、任意 |
| 发送REST请求 | RestTemplate | WebClient |
Mono: 返回0|1 数据流
Flux:返回N数据流
WebFlux
底层基于Netty实现的Web容器与请求/响应处理机制
Spring WebFlux :: Spring Framework
引入
1 | <parent> |
Context 响应式上下文数据传递; 由下游传播给上游;
以前: 浏览器 –> Controller –> Service –> Dao: 阻塞式编程
**现在: Dao(数据源查询对象【数据发布者】) –> Service –> Controller –> 浏览器: 响应式
大数据流程: 从一个数据源拿到大量数据进行分析计算;
ProductVistorDao.loadData()
.distinct()
.map()
.filter()
.handle()
.subscribe();
//加载最新的商品浏览数据
Reactor Core
HttpHandler、HttpServer
1 | public static void main(String[] args) throws IOException { |
DispatcherHandler
SpringMVC: DispatcherServlet;
SpringWebFlux: DispatcherHandler
请求处理流程
- HandlerMapping:请求映射处理器; 保存每个请求由哪个方法进行处理
- HandlerAdapter:处理器适配器;反射执行目标方法
- HandlerResultHandler:处理器结果处理器;
SpringMVC: DispatcherServlet 有一个 doDispatch() 方法,来处理所有请求;
WebFlux: DispatcherHandler 有一个 handle() 方法,来处理所有请求;
1 | public Mono<Void> handle(ServerWebExchange exchange) { |
- 1、请求和响应都封装在 ServerWebExchange 对象中,由handle方法进行处理
- 2、如果没有任何的请求映射器; 直接返回一个: 创建一个未找到的错误; 404; 返回Mono.error;终结流
- 3、跨域工具,是否跨域请求,跨域请求检查是否复杂跨域,需要预检请求;
- 4、Flux流式操作,先找到HandlerMapping,再获取handlerAdapter,再用Adapter处理请求,期间的错误由onErrorResume触发回调进行处理;
源码中的核心两个:
- handleRequestWith: 编写了handlerAdapter怎么处理请求
- handleResult: String、User、ServerSendEvent、Mono、Flux …
concatMap: 先挨个元素变,然后把变的结果按照之前元素的顺序拼接成一个完整流
1 | private <R> Mono<R> createNotFoundError() { |
注解开发
目标方法传参
Method Arguments :: Spring Framework
| Controller method argument | Description |
|---|---|
| ServerWebExchange | 封装了请求和响应对象的对象; 自定义获取数据、自定义响应 |
| ServerHttpRequest, ServerHttpResponse | 请求、响应 |
| WebSession | 访问Session对象 |
| java.security.Principal | |
| org.springframework.http.HttpMethod | 请求方式 |
| java.util.Locale | 国际化 |
| java.util.TimeZone + java.time.ZoneId | 时区 |
| @PathVariable | 路径变量 |
| @MatrixVariable | 矩阵变量 |
| @RequestParam | 请求参数 |
| @RequestHeader | 请求头; |
| @CookieValue | 获取Cookie |
| @RequestBody | 获取请求体,Post、文件上传 |
| HttpEntity | 封装后的请求对象 |
| @RequestPart | 获取文件上传的数据 multipart/form-data. |
| java.util.Map, org.springframework.ui.Model, and org.springframework.ui.ModelMap. | Map、Model、ModelMap |
| @ModelAttribute | |
| Errors, BindingResult | 数据校验,封装错误 |
| SessionStatus + class-level @SessionAttributes | |
| UriComponentsBuilder | For preparing a URL relative to the current request’s host, port, scheme, and context path. See URI Links. |
| @SessionAttribute | |
| @RequestAttribute | 转发请求的请求域数据 |
| Any other argument | 所有对象都能作为参数: 1、基本类型 ,等于标注@RequestParam 2、对象类型,等于标注 @ModelAttribute |
返回值写法
sse和websocket区别:
- SSE:单工;请求过去以后,等待服务端源源不断的数据
- websocket:双工: 连接建立后,可以任何交互;
| Controller method return value | Description |
|---|---|
| @ResponseBody | 把响应数据写出去,如果是对象,可以自动转为json |
| HttpEntity, ResponseEntity | ResponseEntity:支持快捷自定义响应内容 |
| HttpHeaders | 没有响应内容,只有响应头 |
| ErrorResponse | 快速构建错误响应 |
| ProblemDetail | SpringBoot3; |
| String | 就是和以前的使用规则一样; forward: 转发到一个地址 redirect: 重定向到一个地址 配合模板引擎 |
| View | 直接返回视图对象 |
| java.util.Map, org.springframework.ui.Model | 以前一样 |
| @ModelAttribute | 以前一样 |
| Rendering | 新版的页面跳转API; 不能标注 @ResponseBody 注解 |
| void | 仅代表响应完成信号 |
| Flux |
使用 text/event-stream 完成SSE效果 |
| Other return values | 未在上述列表的其他返回值,都会当成给页面的数据; |
文件上传
Multipart Content :: Spring Framework
1 | class MyForm { |
现在:
1 |
|
错误处理
1 |
|
RequestContext
自定义Flux配置
WebFluxConfigurer
容器中注入这个类型的组件,重写底层逻辑
1 |
|
Filter
1 |
|
R2DBC
Web、网络、IO(存储)、中间件(Redis、MySQL)
应用开发:
- 网络
- 存储:MySQL、Redis
- Web:Webflux
- 前端; 后端:Controller – Service – Dao(r2dbc;mysql)
数据库:
- 导入驱动; 以前:JDBC(jdbc、各大驱动mysql-connector); 现在:r2dbc(r2dbc-spi、各大驱动 r2dbc-mysql)
- 驱动:
- 获取连接
- 发送SQL、执行
- 封装数据库返回结果
R2dbc
用法:
1、导入驱动: 导入连接池(r2dbc-pool)、导入驱动(r2dbc-mysql )
2、使用驱动提供的API操作
1 | <dependency> |
1 |
|
Spring Data R2DBC
提升生产力方式的 响应式数据库操作
整合
1、导入依赖
1 | <!-- https://mvnrepository.com/artifact/io.asyncer/r2dbc-mysql --> |
2、编写配置
1 | spring: |
声明式接口:R2dbcRepository
Repository接口
1 |
|
自定义Converter
1 | package com.atguigu.r2dbc.config.converter; |
配置生效
1 | //开启 R2dbc 仓库功能;jpa |
编程式组件
- R2dbcEntityTemplate
- DatabaseClient
RBAC-SQL练习
1-1
- 自定义 Converter<Row,Bean> 方式
@Bean 1
2
3
4
5
6
7
8
9R2dbcCustomConversions r2dbcCustomConversions(){
List<Converter<?, ?>> converters = new ArrayList<>();
converters.add(new BookConverter());
return R2dbcCustomConversions.of(MySqlDialect.INSTANCE, converters);
}
//1-1: 结合自定义 Converter
bookRepostory.hahaBook(1L)
.subscribe(tBook -> System.out.println("tBook = " + tBook));
- 编程式封装方式: 使用DatabaseClient
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//1-1:第二种方式
databaseClient.sql("select b.*,t.name as name from t_book b " +
"LEFT JOIN t_author t on b.author_id = t.id " +
"WHERE b.id = ?")
.bind(0, 1L)
.fetch()
.all()
.map(row-> {
String id = row.get("id").toString();
String title = row.get("title").toString();
String author_id = row.get("author_id").toString();
String name = row.get("name").toString();
TBook tBook = new TBook();
tBook.setId(Long.parseLong(id));
tBook.setTitle(title);
TAuthor tAuthor = new TAuthor();
tAuthor.setName(name);
tAuthor.setId(Long.parseLong(author_id));
tBook.setAuthor(tAuthor);
return tBook;
})
.subscribe(tBook -> System.out.println("tBook = " + tBook));
1-N
- 使用底层API DatabaseClient;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
void oneToN() throws IOException {
// databaseClient.sql("select a.id aid,a.name,b.* from t_author a " +
// "left join t_book b on a.id = b.author_id " +
// "order by a.id")
// .fetch()
// .all(row -> {
//
// })
// 1~6
// 1:false 2:false 3:false 4: true 8:true 5:false 6:false 7:false 8:true 9:false 10:false
// [1,2,3]
// [4,8]
// [5,6,7]
// [8]
// [9,10]
// bufferUntilChanged:
// 如果下一个判定值比起上一个发生了变化就开一个新buffer保存,如果没有变化就保存到原buffer中
// Flux.just(1,2,3,4,8,5,6,7,8,9,10)
// .bufferUntilChanged(integer -> integer%4==0 )
// .subscribe(list-> System.out.println("list = " + list));
; //自带分组
Flux<TAuthor> flux = databaseClient.sql("select a.id aid,a.name,b.* from t_author a " +
"left join t_book b on a.id = b.author_id " +
"order by a.id")
.fetch()
.all()
.bufferUntilChanged(rowMap -> Long.parseLong(rowMap.get("aid").toString()))
.map(list -> {
TAuthor tAuthor = new TAuthor();
Map<String, Object> map = list.get(0);
tAuthor.setId(Long.parseLong(map.get("aid").toString()));
tAuthor.setName(map.get("name").toString());
//查到的所有图书
List<TBook> tBooks = list.stream()
.map(ele -> {
TBook tBook = new TBook();
tBook.setId(Long.parseLong(ele.get("id").toString()));
tBook.setAuthorId(Long.parseLong(ele.get("author_id").toString()));
tBook.setTitle(ele.get("title").toString());
return tBook;
})
.collect(Collectors.toList());
tAuthor.setBooks(tBooks);
return tAuthor;
});//Long 数字缓存 -127 - 127;// 对象比较需要自己写好equals方法
flux.subscribe(tAuthor -> System.out.println("tAuthor = " + tAuthor));
System.in.read();
}
最佳实践
最佳实践: 提升生产效率的做法
- 1、Spring Data R2DBC,基础的CRUD用 R2dbcRepository 提供好了
- 2、自定义复杂的SQL(单表): @Query;
- 3、多表查询复杂结果集: DatabaseClient 自定义SQL及结果封装;
- @Query + 自定义 Converter 实现结果封装
经验:
- 1-1:1-N 关联关系的封装都需要自定义结果集的方式
- Spring Data R2DBC:
- 自定义Converter指定结果封装
- DatabaseClient:贴近底层的操作进行封装; 见下面代码
- MyBatis: 自定义 ResultMap 标签去来封装
1 | databaseClient.sql("select b.*,t.name as name from t_book b " + |
附录
- RBAC SQL文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73-- 用户表
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user`(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '用户名',
`password` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '密码',
`email` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '邮箱',
`phone` char(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '电话',
`create_time` datetime(0) NOT NULL COMMENT '创建时间',
`update_time` datetime(0) NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- 角色表
DROP TABLE IF EXISTS `t_roles`;
CREATE TABLE `t_roles`(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '角色名',
`value` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '角色的英文名',
`create_time` datetime(0) NOT NULL,
`update_time` datetime(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- 权限表(资源表)
DROP TABLE IF EXISTS `t_perm`;
CREATE TABLE `t_perm`(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`value` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '权限字段',
`uri` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '资源路径',
`description` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '资源描述',
`create_time` datetime(0) NOT NULL,
`update_time` datetime(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- 用户角色关系表
DROP TABLE IF EXISTS `t_user_role`;
CREATE TABLE `t_user_role`(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) NOT NULL,
`role_id` bigint(20) NOT NULL,
`create_time` datetime(0) NOT NULL,
`update_time` datetime(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- 角色权限关系表
DROP TABLE IF EXISTS `t_role_perm`;
CREATE TABLE `t_role_perm`(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`role_id` bigint(20) NOT NULL,
`perm_id` bigint(20) NOT NULL,
`create_time` datetime(0) NOT NULL,
`update_time` datetime(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- 图书&作者表
CREATE TABLE `t_book`(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`author_id` bigint(20) NOT NULL,
`publish_time` datetime(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
CREATE TABLE `t_author`(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
Spring Security Reactive
目标:
SpringBoot + Webflux + Spring Data R2DBC + Spring Security
整合
1 | <dependencies> |
开发
应用安全
- 防止攻击:
- DDos、CSRF、XSS、SQL注入…
- 控制权限
- 登录的用户能干什么。
- 用户登录系统以后要控制住用户的所有行为,防止越权;
- 传输加密
- https
- X509
- 认证:
- OAuth2.0
- JWT
RBAC权限模型
Role Based Access Controll: 基于角色的访问控制
一个网站有很多用户: zhangsan
每个用户可以有很多角色:
一个角色可以关联很多权限:
一个人到底能干什么?
权限控制:
- 找到这个人,看他有哪些角色,每个角色能拥有哪些权限。 这个人就拥有一堆的 角色 或者 权限
- 这个人执行方法的时候,我们给方法规定好权限,由权限框架负责判断,这个人是否有指定的权限
所有权限框架:
- 让用户登录进来: 认证(authenticate):用账号密码、各种其他方式,先让用户进来
- 查询用户拥有的所有角色和权限: 授权(authorize): 每个方法执行的时候,匹配角色或者权限来判定用户是否可以执行这个方法
认证
登录行为
静态资源放行
其他请求需要登录
1 | package com.atguigu.security.config; |
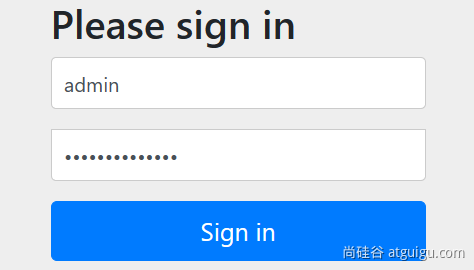
这个界面点击登录,最终Spring Security 框架会使用 ReactiveUserDetailsService 组件,按照 表单提交的用户名 去数据库查询这个用户详情(基本信息 [账号、密码],角色,权限);
把数据库中返回的 用户详情 中的密码 和 表单提交的密码进行比对。比对成功则登录成功
1 | package com.atguigu.security.component; |
授权
@EnableReactiveMethodSecurity
1 | package com.atguigu.security.controller; |
官方示例:GitHub - spring-projects/spring-security-samples
配置是: SecurityWebFilterChain
1 | package com.atguigu.security.config; |